On February 3rd, Axios released President Trump’s daily schedule. As in many other areas of his political career, Trump has broken with tradition by hiding his schedule from public view.
In addition to a set of re-typed PDF files, Axios also created a Google Spreadsheet containing the president’s schedule and notes about the activities. If you’re interesting in reading about how that task could be accomplished, I highly recommend Maëlle Salmon’s post on rectangling the tables in the PDF files.
The leak and subsequent release by Axios provide unique insight into Trump’s daily activities, which are dominated by a large block of time referred to as Executive Time. Reportedly, Trump hated following a strict daily schedule, so former chief-of-staff John Kelly introduced the concept of Executive Time: unstructured time when the president reads watches news, makes phone calls, and writes emails tweets.
I won’t comment extensively on what these schedules mean—for more on that angle, see reporting from Axios, Vox, Politico and others.
Instead, I’ll use this post to visualize the president’s work day and tweeting habits and a demonstrate how to use R, plot.ly and the tools of the tidyverse to create interactive and static visualizations to try to make sense of what the president does on a daily basis.
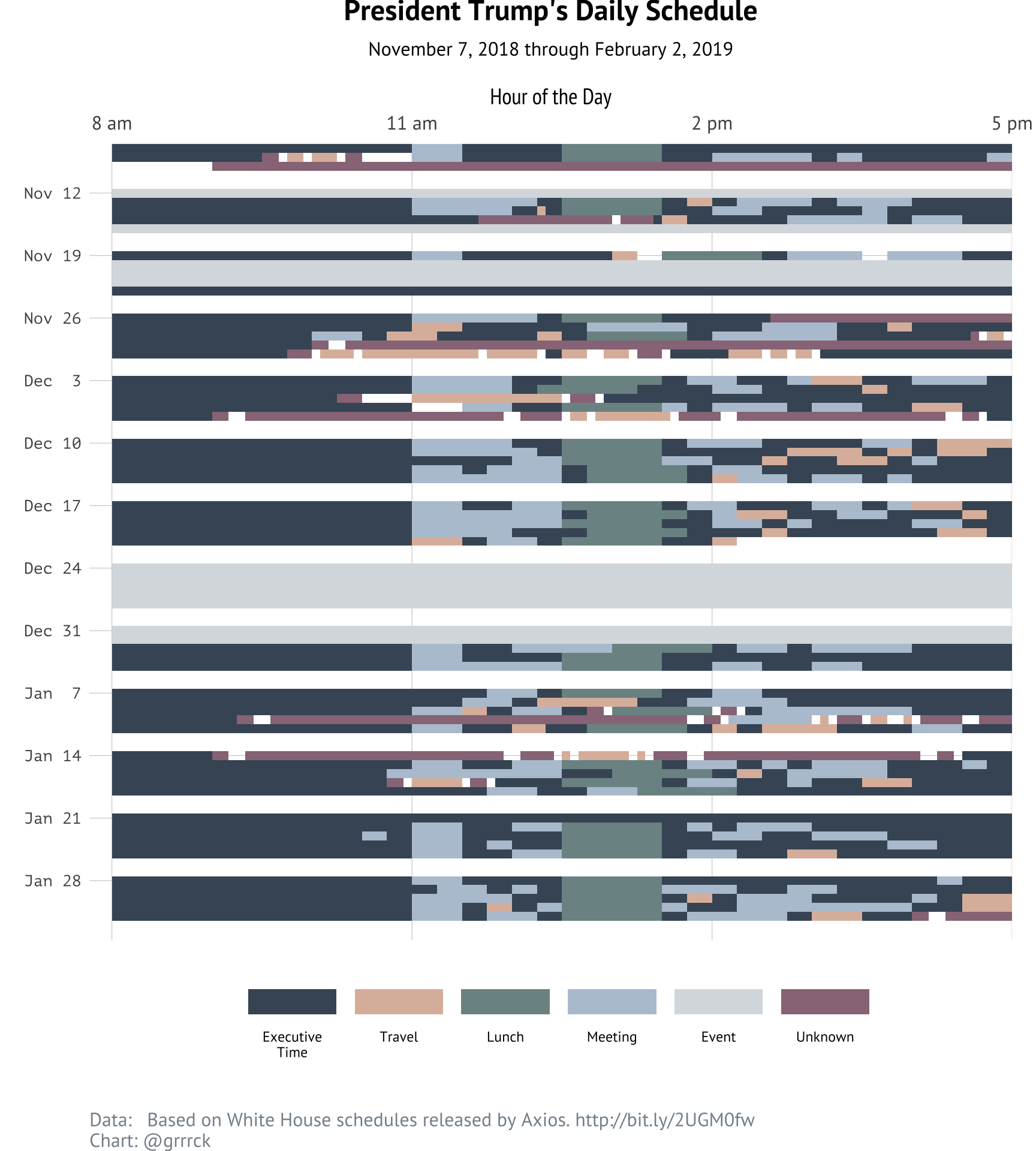
The President’s Daily 8am to 5pm Schedule
Axios’ article on Trump’s private schedule includes an interactive view of the president’s workday schedule from 8 a.m. to 5 p.m. Here, I recreate the same visualization, with each activity colored according to the activity’s category. (Note these plots look best on desktop devices.)
Hover over any time slot to view more details about the activity at that time. You can also toggle activity categories — try removing everything except Meetings, Lunches, and Events, it’s unbelievable.
View static image of the plot. Expand the section below for a behind-the-scenes look at this visualization.
{kind=link}
NoneHow This Was Made…
The pipeline for building this visualization is a fairly standard loading and transformation of the source data with readr and dplyr, followed by building the visualization in ggplot2 and passing off to plotly for the interactive parts. On the other hand, I created a number of helper functions and constants that I reused throughout this post, so there’s quite a bit of code and preamble to get to the actual plot making.
library(tidyverse)
library(plotly)
library(lubridate)
library(glue)
library(hrbrthemes)
library(showtext)
library(sysfonts)Load the Axios Data
# Convert datetime to decimal hour of day
in_hours <- function(x) {
hour(x) + minute(x)/60 + second(x)/60^2
}
executive_categories <- c(
"executive_time" = "Executive Time",
"event" = "Event",
"lunch" = "Lunch",
"meeting" = "Meeting",
"no_data" = "Unknown",
"travel" = "Travel"
)
# Exec Time Downloaded from http://bit.ly/2Sk9Vj7
exec_time <-
read_csv(
here::here(
"_data", "trump-exec-time",
"axios_trump_schedule_2018-11-07--2019-02-02.csv"
),
col_types = cols(.default = col_character())
) %>%
mutate(
# Convert time start/end to datetime
event_id = row_number(),
time_start = paste(date, time_start),
time_end = paste(date, time_end),
time_start = ymd_hm(time_start, tz = "America/New_York"),
time_end = ymd_hm(time_end, tz = "America/New_York"),
time_end = if_else(time_start > time_end,
time_end + hours(24), time_end),
# Recode the activity category with nicer labels
top_category = factor(top_category,
levels = names(executive_categories),
labels = executive_categories)
) %>%
mutate(
# Create label pieces for plotly hover text
label_title = glue("<b>{top_category}</b>"),
has_uniq_title = tolower(top_category) != tolower(listed_title),
has_subtitle = has_uniq_title & !is.na(listed_title),
label_subtitle = if_else(has_subtitle,
glue("<br><em>{listed_title}</em>"), ""),
has_location = !is.na(listed_location),
label_location = if_else(has_location,
glue("<br><em>{listed_location}</em>"), ""),
label_time = glue(
"<br><br>{strftime(time_start, '%A, %B %e %H:%M')} ",
"to {strftime(time_end, '%H:%M')}"),
has_notes = !is.na(notes),
label_notes = if_else(has_notes, paste0("<br><br>", notes), ""),
# Compose final tooltip text
label = paste0(label_title, label_subtitle, label_location,
label_time, label_notes)
) %>%
mutate(
# truncate any activities that span 8am or 5pm
time_start = if_else(
in_hours(time_start) < 8 & in_hours(time_end) > 8,
floor_date(time_start, "day") + hours(8),
time_start
),
time_end = if_else(
in_hours(time_start) < 17 & in_hours(time_end) > 17,
floor_date(time_end, "day") + hours(17),
time_end
),
# create 5 minute increments "inside" each activity
time_inc = map2(time_start, time_end, seq, by = "5 mins")
) %>%
select(event_id, time_start, time_end, time_inc,
listed_title, top_category, label)
glimpse(exec_time)Rows: 577
Columns: 7
$ event_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
$ time_start <dttm> 2018-11-07 08:00:00, 2018-11-07 11:00:00, 2018-11-07 11:…
$ time_end <dttm> 2018-11-07 11:00:00, 2018-11-07 11:30:00, 2018-11-07 12:…
$ time_inc <list> <2018-11-07 08:00:00, 2018-11-07 08:05:00, 2018-11-07 08…
$ listed_title <chr> "Executive time", "Meeting with the chief of staff", "Exe…
$ top_category <fct> Executive Time, Meeting, Executive Time, Lunch, Executive…
$ label <chr> "<b>Executive Time</b><br><em>Oval office</em><br><br>Wed…Prepare to Make a Plot
To build the plot, I first created several helper functions for the plot labels, scales, and data filtering. I also set the global plot theme, and created a few constants that I used across several plots in this post.
Plot Constants
I created a few constants for later reference: one stores date breaks for the time period covered by the Axios schedule, with labels on each Monday; and the other two store the color palette and labels for the executive activity categories. The colors were hand-selected from a picture of the Donald (I was expecting there to be more orange).
plot_date_breaks <- seq(
from = ymd_h("2018-11-12 0", tz = "America/New_York"),
to = max(exec_time$time_start),
by = "7 day"
)
plot_date_breaks_labels <- strftime(plot_date_breaks, "%b %e")
plot_date_breaks <- as.integer(plot_date_breaks)
event_type_colors <- c(
"Executive Time" = "#445566",
"Travel" = "#997788",
"Lunch" = "#7c9393",
"Meeting" = "#b7c6d6",
"Event" = "#ddbbaa",
"Unknown" = "#d9dde0")
event_type_labels <- sub(" ", "\n", names(event_type_colors))
Build the Actual Plot Already!
Finally, I pulled the schedule data and all of the above pieces together to build the interactive plot.
g <-
exec_time %>%
mutate(
date = floor_date(time_start, "day"),
date = as.integer(date)
) %>%
filter_workday() %>%
mutate_at(vars(time_start, time_end), in_hours) %>%
ggplot() +
geom_rect(
aes(xmin = time_start,
xmax = time_end,
ymin = date - 3600 * 12,
ymax = date + 3600 * 12,
fill = top_category
)
) +
scale_x_continuous(
breaks = seq(8, 17, 3),
limits = c(8, 17),
position = "top",
labels = am_pm(seq(8, 17, 3)),
expand = expansion(c(0.025, 0), 0)
) +
scale_y_reverse(
# trans = rev_date,
breaks = plot_date_breaks,
labels = plot_date_breaks_labels,
expand = expansion(c(0.025, 0), 0)
) +
scale_fill_manual(
values = event_type_colors,
labels = event_type_labels
) +
labs(x = "Hour of the Day", y = NULL, fill = NULL) +
ggtitle(
"President Trump's Daily Schedule",
"November 7, 2018 through February 2, 2019"
) +
labs(caption = credit_caption(FALSE)) +
guides(fill = guide_legend(nrow = 1, label.position = "bottom")) +
theme(
axis.text.y = element_text(family = "PT Mono", size = 10),
plot.margin = margin(3, 0, 0, 0, unit = "line")
)
plotly::ggplotly(g + aes(text = label), tooltip = "label") %>%
plotly::layout(xaxis = list(side = "top", title = ""))And that’s it! Jump back up to see the final product.
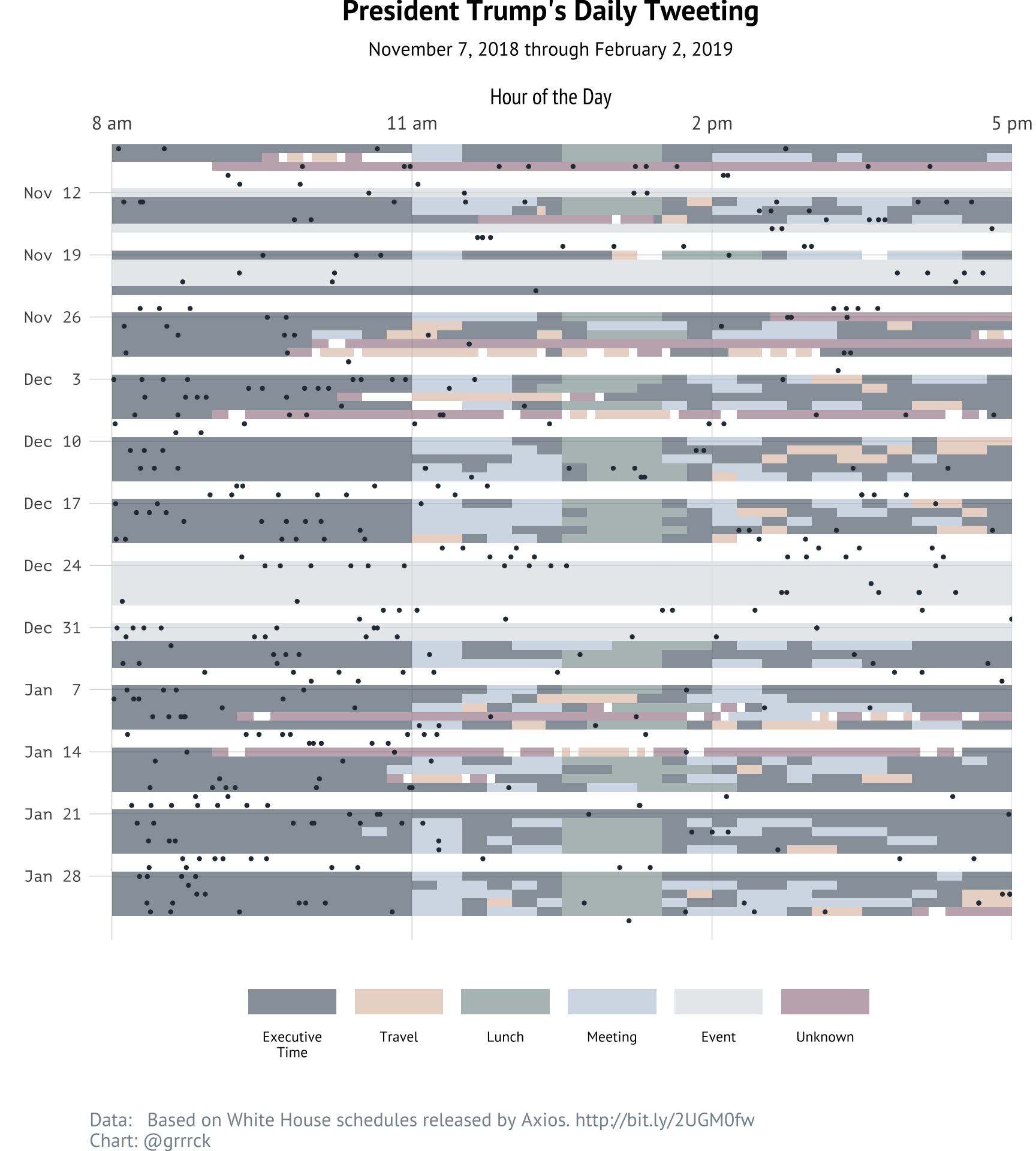
The President’s Daily Tweeting Schedule
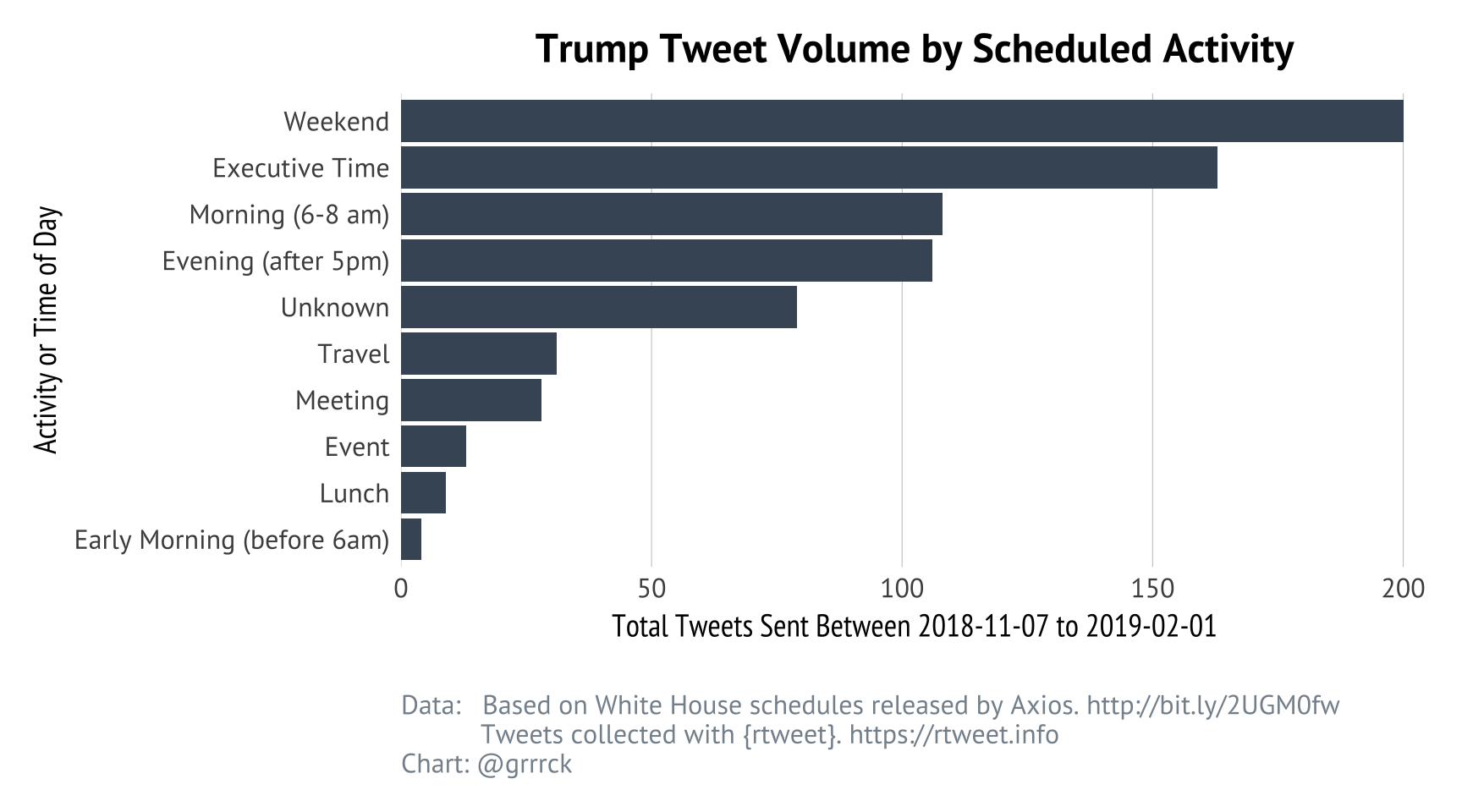
Donald Trump tweets about 5.1 tweets per working day within working hours. Why does this number feel so low? Then again, this represents 290 tweets published over 57 workdays and 128 tweets over the 24 weekend days in the same time period. Outside of work hours, the average rises to 8.7 tweets per 24-hour workday, or a total of 546 tweets on workdays and 203 tweets on weekends.
Below, each tweet sent by the President is shown as a dot over his private schedule. Hover over a tweet’s dot to read the text of the tweet.
View static image of the plot. Expand the section below to learn more about how I gathered tweets from @realDonaldTrump, merged his tweets with the Axios schedules, and added them to the first plot.
{kind=link}
Also, if you’re interested in exploring the timeline of tweets rendered as they appear on Twitter, Jonathan Sidi created an awesome Shiny app for exploring Trump’s tweets by category.
How much time is spent in Executive Time?
Looking at the above plots, it’s really striking how much time is unstructured Executive Time in Trump’s schedule. But how much of the day is spent in each activity group?
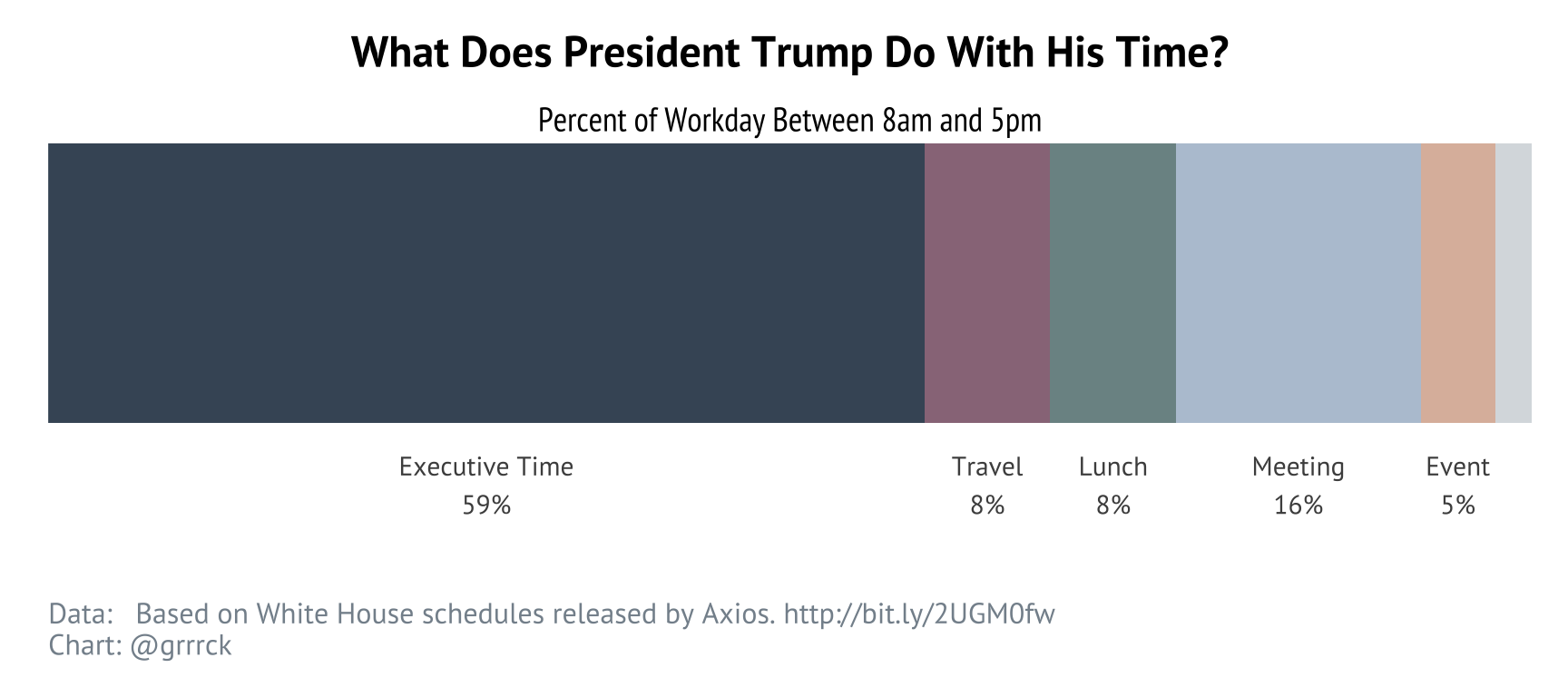
For 43 of the 51 workdays (that’s 84%) covered by the Axios schedules and for which there is schedule information, Trump spent 50% or more of his day in executive time.
In other words, there were only 8 days in about 10 work weeks where executive time was not the dominant activity.
When the above time-use summary is expanded into his daily schedule, it’s clear how unusual it is for Trump to spend a significant portion of his day in structured events.
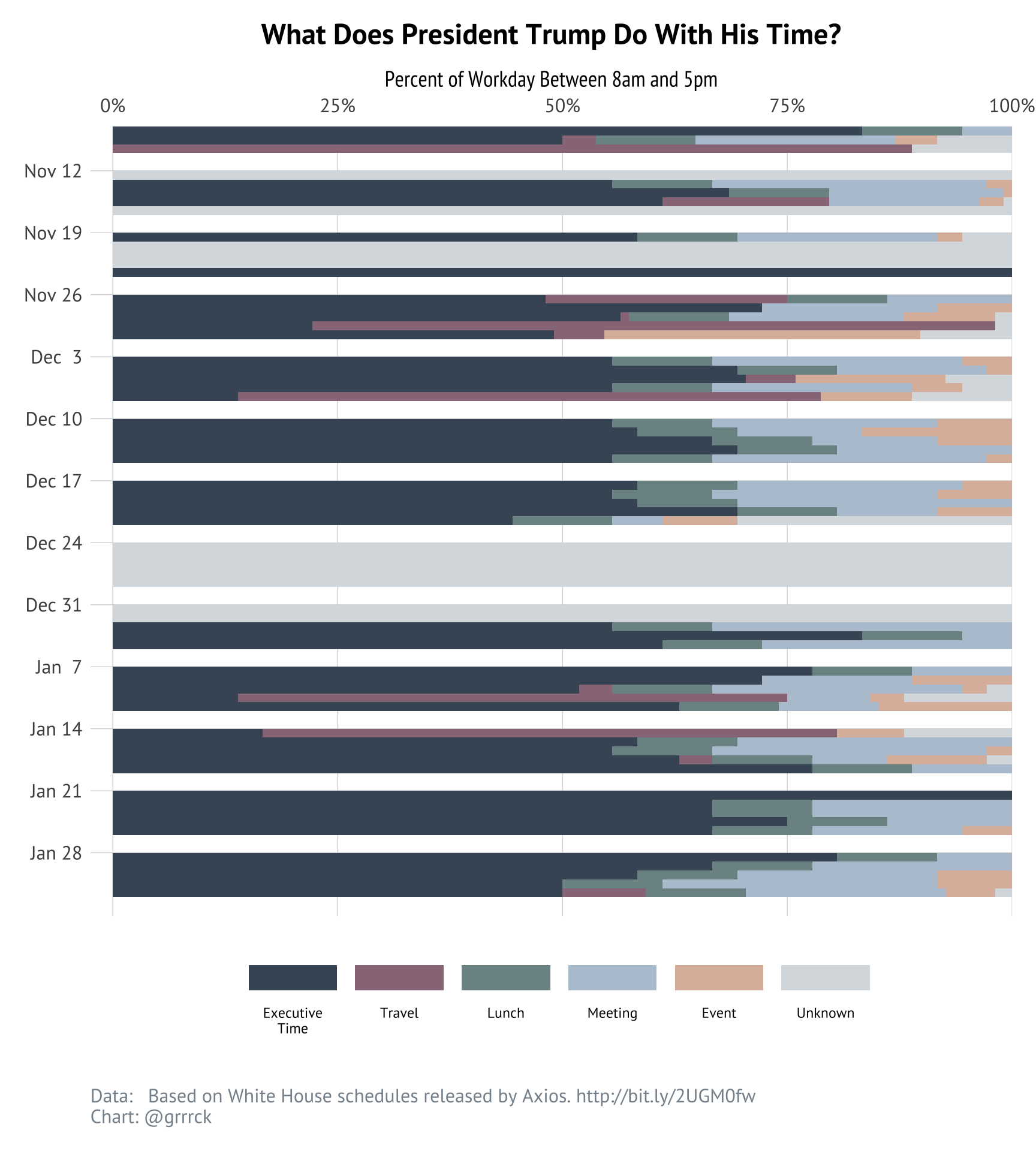
In fact, the largest non-executive time block for the 8 days where executive time isn’t more than half of Trump’s workday are almost entirely travel related.
| Date | Duration | Longest Non-Executive-Time Activity |
|---|---|---|
| 2018-11-09 | 6.50 hours | Depart Washington, DC en route Orly, France |
| 2018-11-26 | 2.17 hours | Depart Gulfport, MS en route Washington, DC |
| 2018-11-29 | 6.67 hours | Depart Washington, DC en route Buenos Aires, Argentina |
| 2018-11-30 | 1.75 hours | G20 Leaders' dinner |
| 2018-12-07 | 2.58 hours | Depart Washington, DC en route Kansas City, MO |
| 2018-12-21 | 1.00 hours | Lunch |
| 2019-01-10 | 4.17 hours | Depart Washington, DC en route McAllen, TX |
| 2019-01-14 | 2.58 hours | Depart Washington, DC en route Kenner, LA |
Travel seems to be the only activity capable of substantially affecting the amount of time the president spends on his executive time. My (completely speculative) guess is that this is in part due to travel being the only activity with a duration long enough to displace executive time, and also in part that travel probably most resembles executive time.
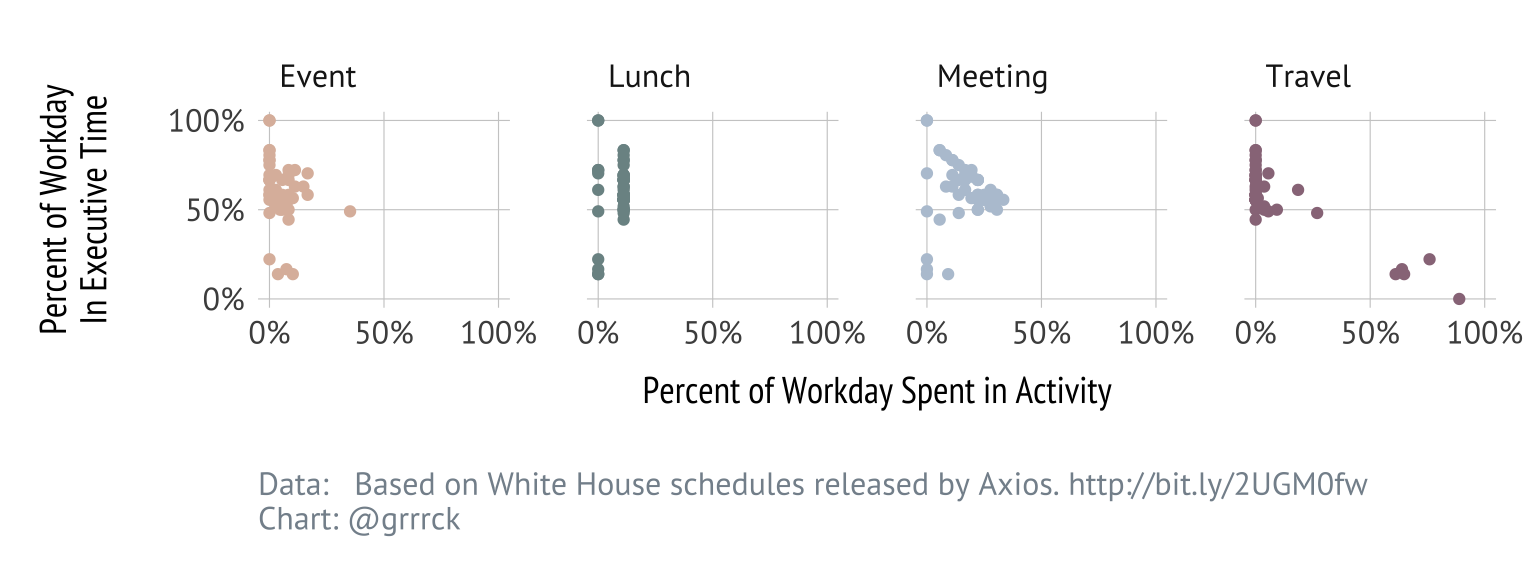
Tweeter In Chief
At the point, I was very interested in exploring how Trump’s tweeting relates to his work schedule. The first question to answer is When does he send most of his tweets? And the answer is: primarily on the weekends, during executive time, or before or after work hours.
We can get a sense of the timing of Trump’s tweeting activities by looking at the time of day of each tweet and the scheduled activity that’s going on at the time. The following plot shows each tweet as a vertical line and considers only workday tweeting and only for days covered by the Axios schedules.
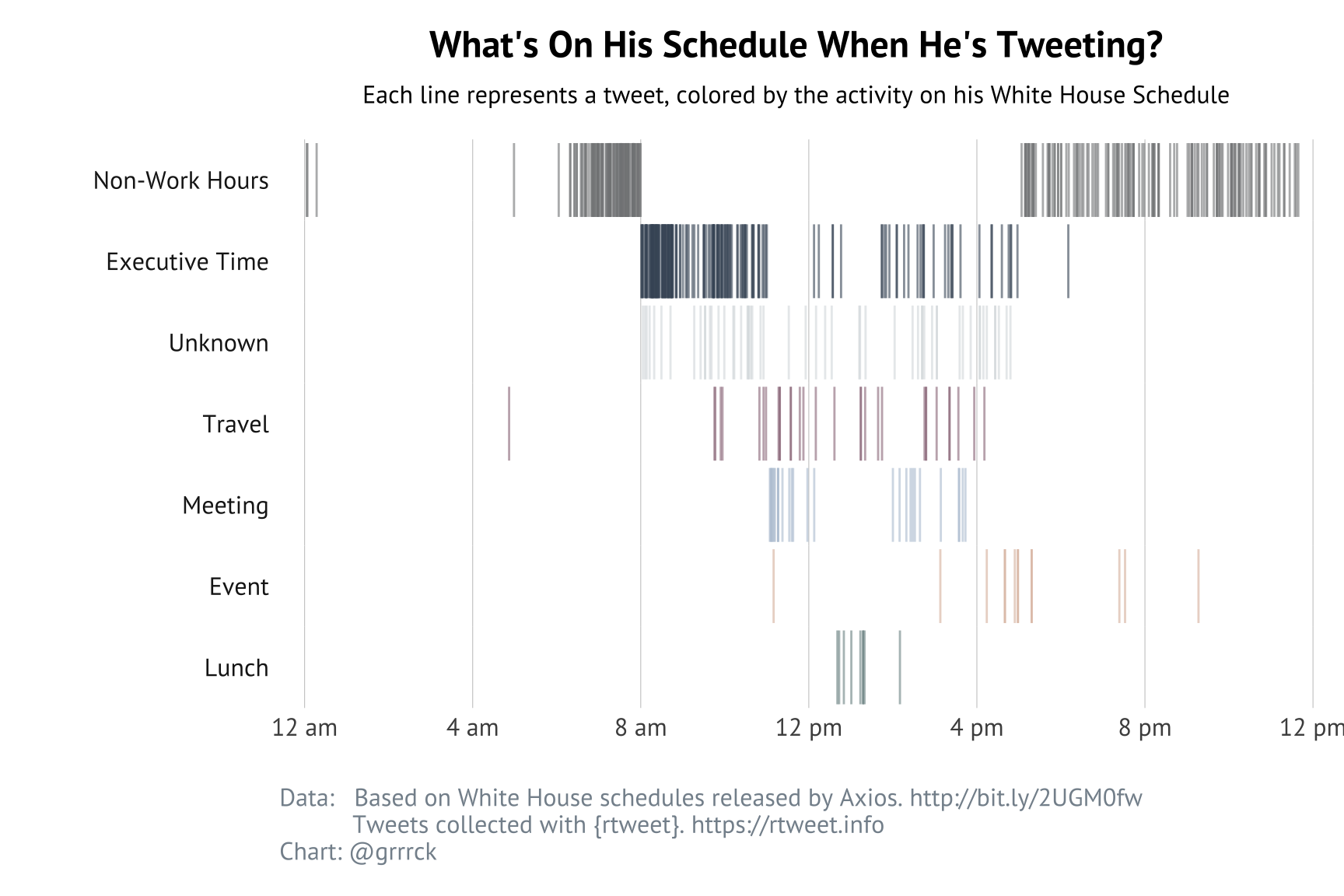
Most of Trump’s tweeting happens betewen 7 and 9 am, but what’s striking is that it’s nearly impossible to tell the difference between early morning tweeting and the start of President Trump’s official workday at 8am.
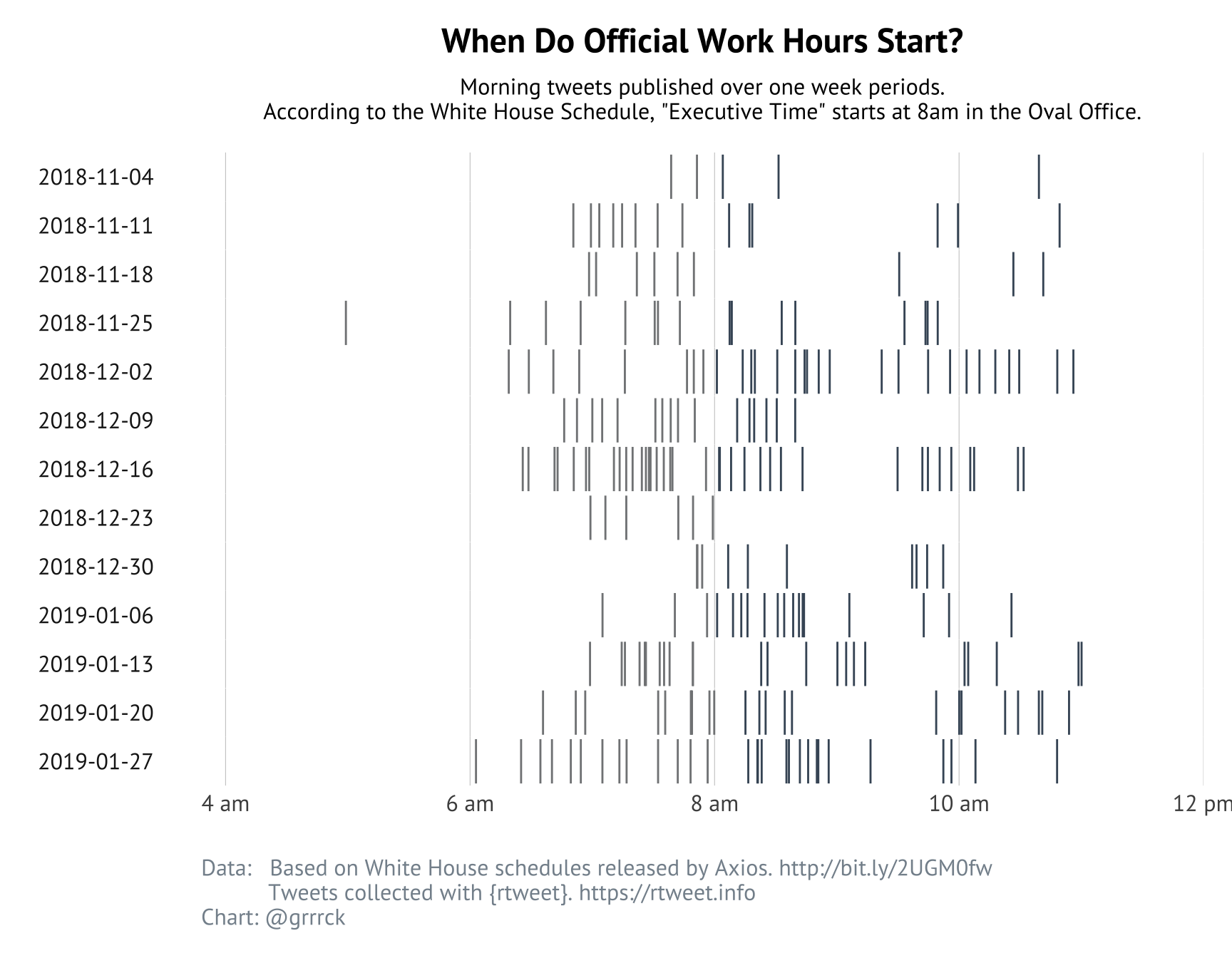
As we learned above, Trump sends about 5 tweets per working day within working hours. Naturally, I wondered if he tends to tweet more or less during the day when he has more executive or travel time available. Similarly does he tweet less when he has more strucured time, i.e. metings, events, or lunches?
Somewhat unsurprisingly, the number of tweets sent during the workday in only very slightly correlated with the amount of unstructured time on Trump’s calendar. This makes sense: there is very little variation in the amount of the day spent in structured events – it’s never more than half the day.
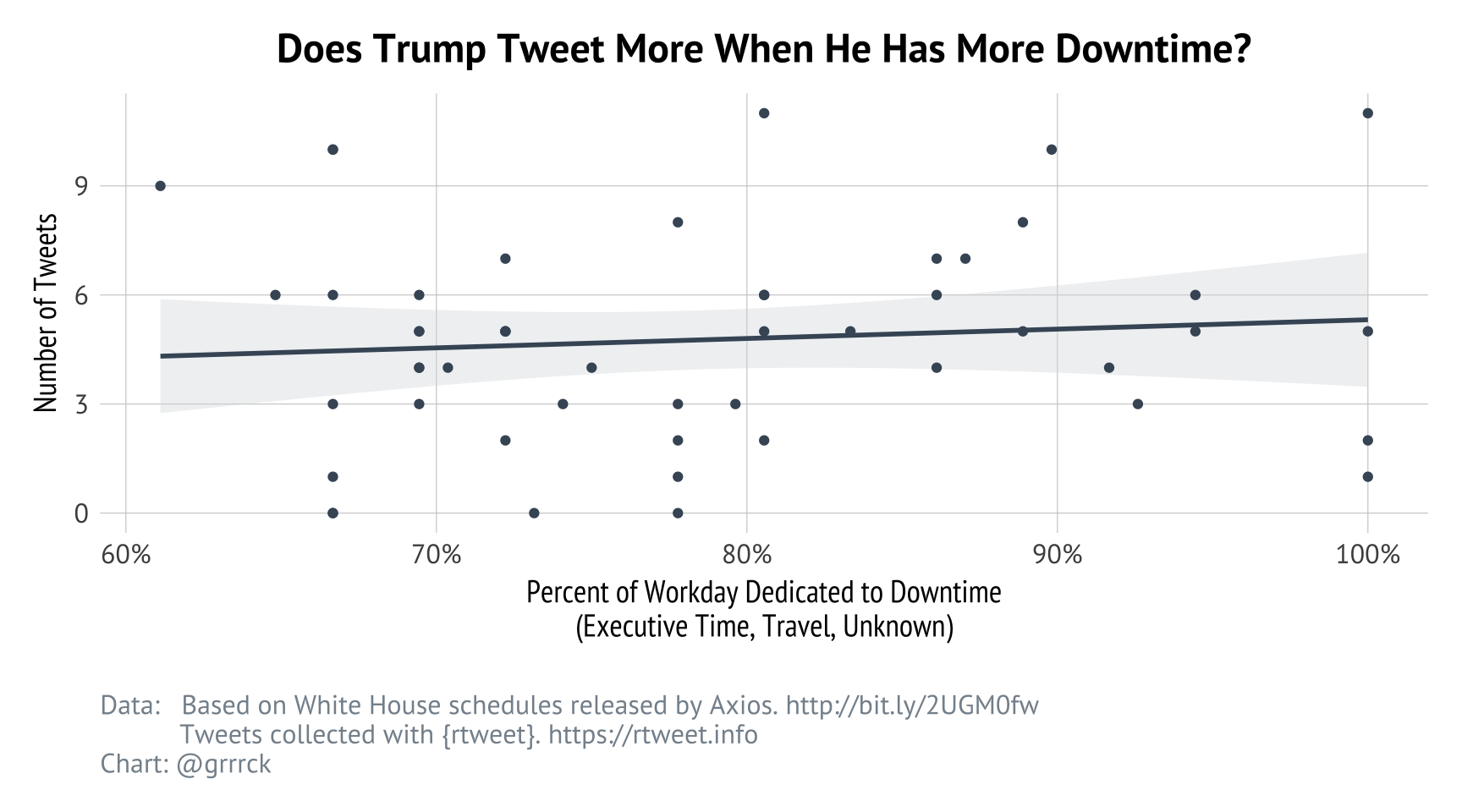
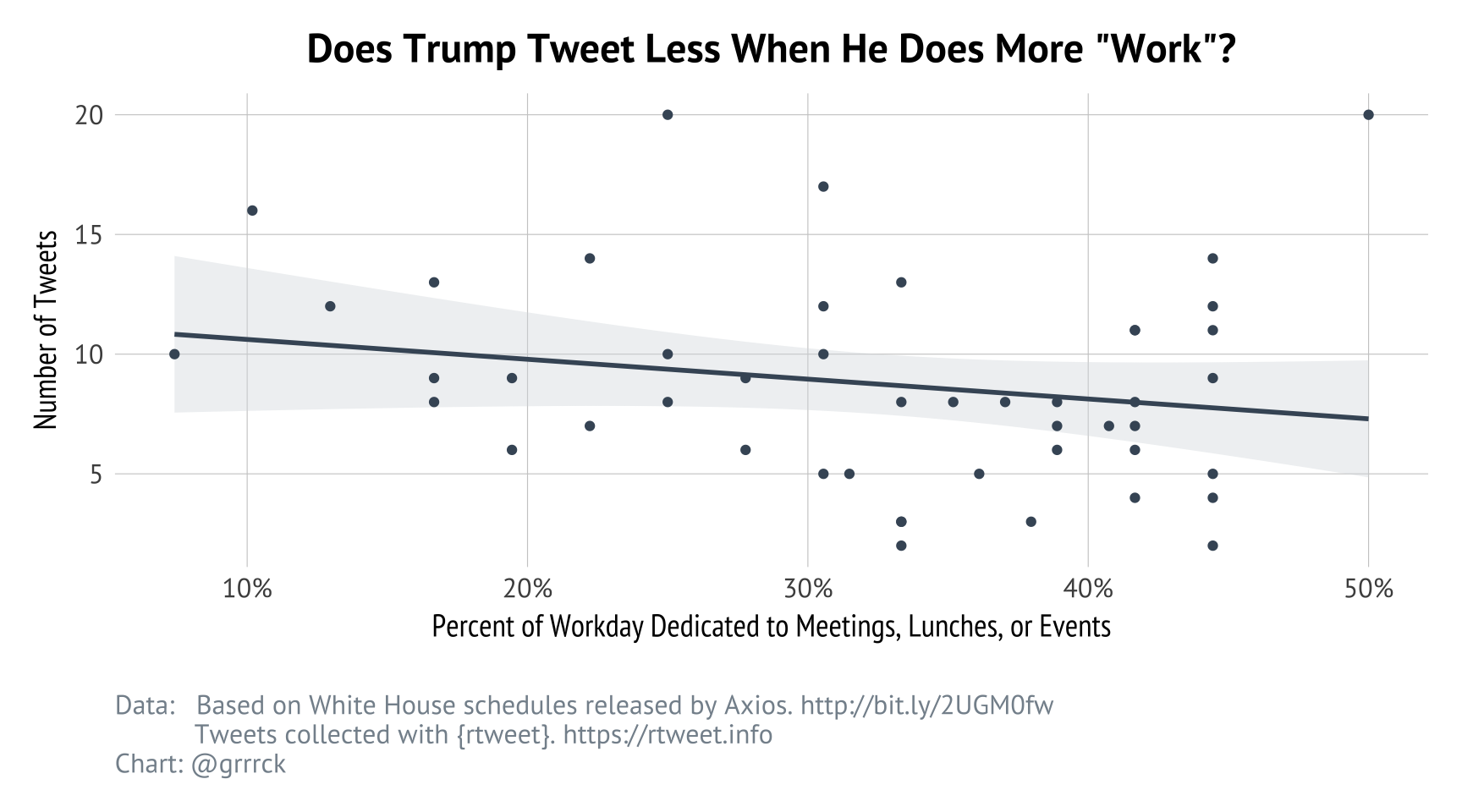
Finally, I wanted to explore the emotional valence of Trump’s day-time tweeting. Are his morning tweets angrier or more rant-driven? Are his event-related tweets more positive?
To this end, I ran Trump’s tweet text through the NRC sentiment dictionary using get_nrc_sentiment() from the syuzhet package. This function returns an integer score from 0 to 10 for a range of positive and negative emotions.
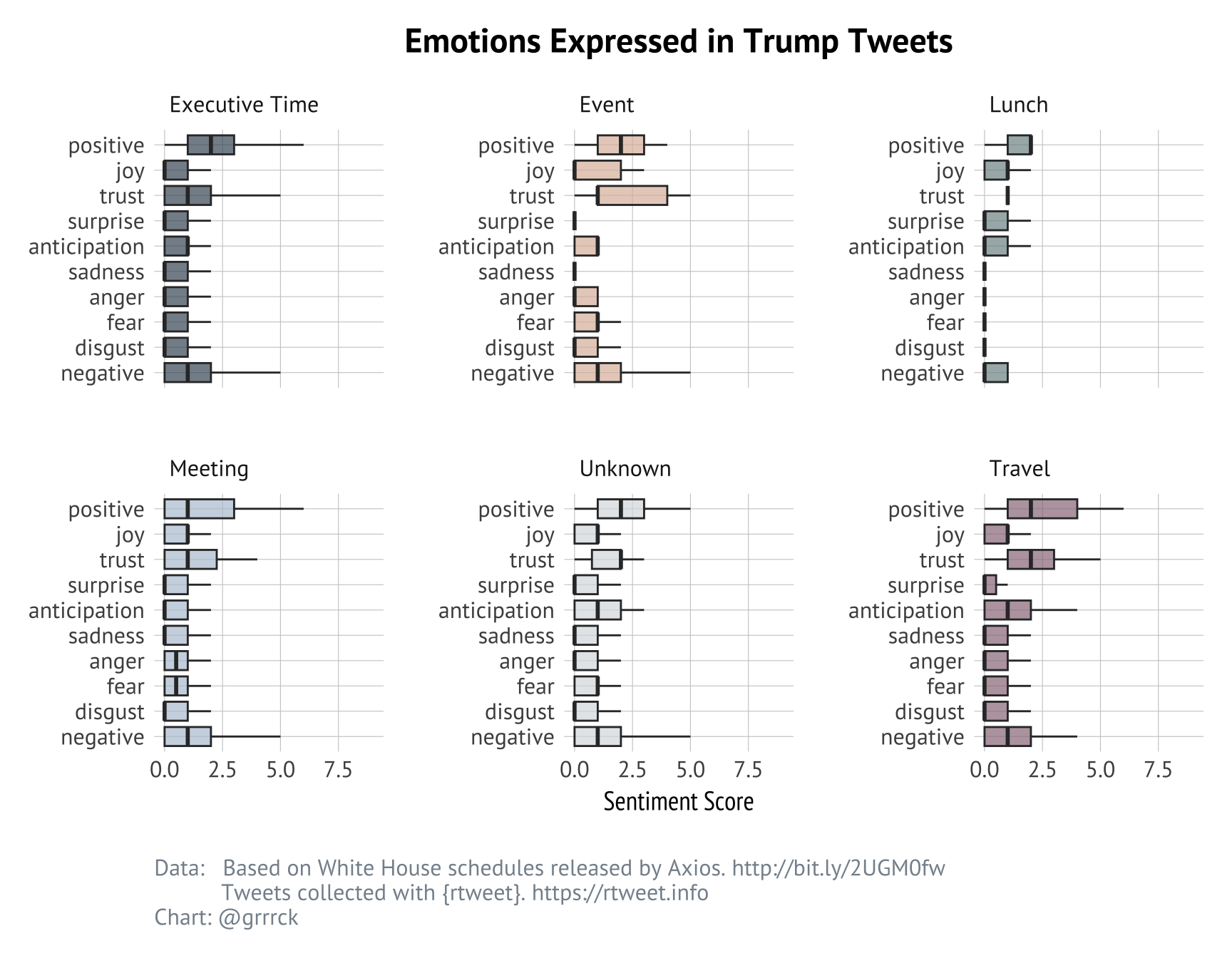
The result provides something of a profile of Trump’s tweeting habits, but more analysis is needed to make sense of these sentiment values. I wanted to look further into how these tweets were categorized by the sentiment dictionary, but by this point this post is already far too long and has consumed too much of my evenings and weekends, so I’ll save it for another day.
Thanks for reading! I’d love to hear your thoughts or feedback. I’m @grrrck on Twitter.