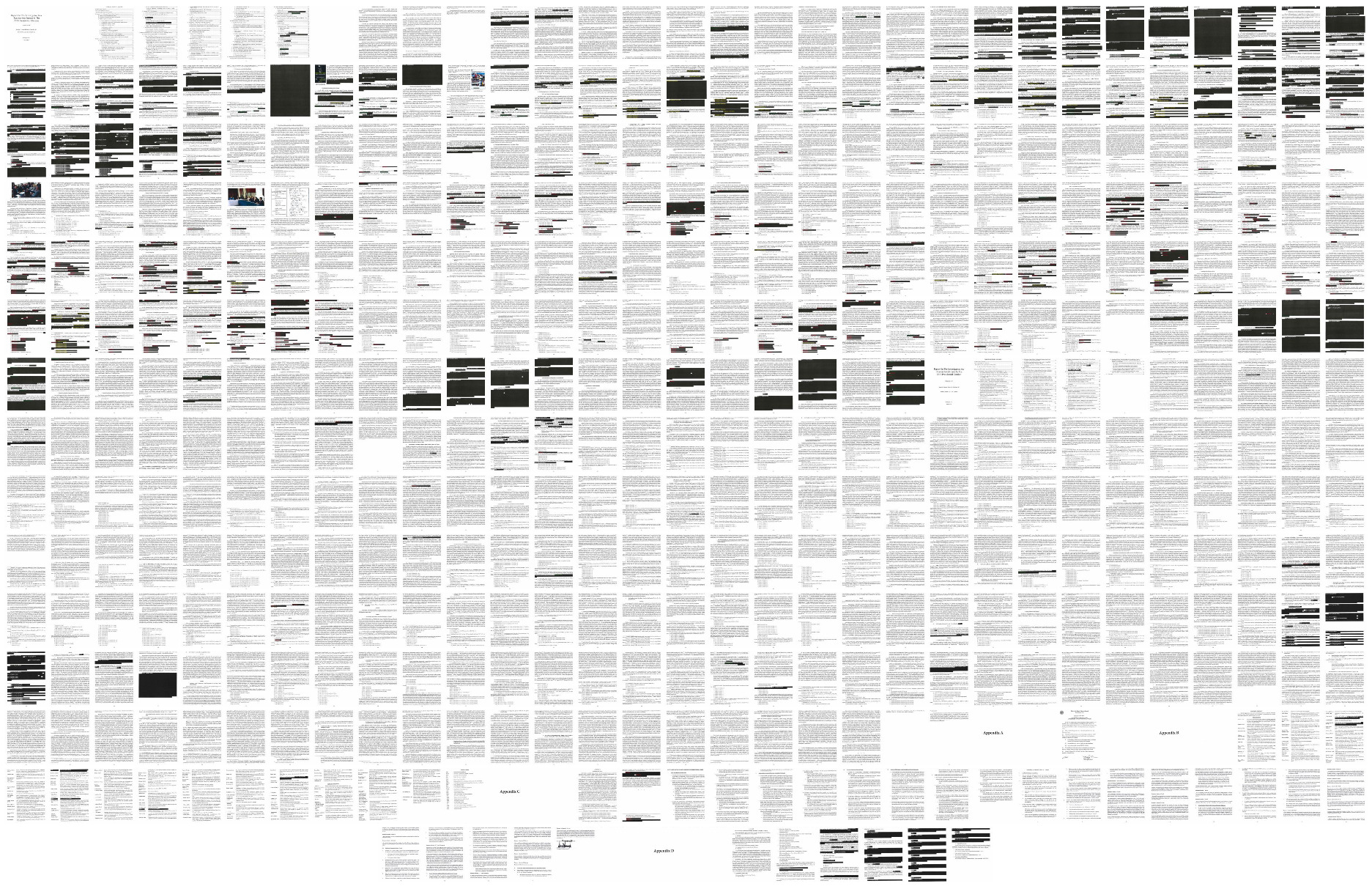
There are many people interested in taking a deeper look at the report, whether within the U.S. government, as citizens, or as data scientists.
Rather than disect the report and its political implications, I’m going to use open-source tools to extract the text from the report. I’m also going to take advantage of the opportunity to use a new R package I’ve been wanting to try, ggpage by Emil Hvitfeldt to visualize the report’s pages and highlight the most-often referenced people in the report.
Extracting the report text with pdftools
I used the pdftools package by ROpenSci to extract the text from the document, using the report posted by @dataeditor of the Washington Post, available here. Extracting the text was as simple as downloading the PDF and running pdftools::pdf_text(). I added page and line numbers to the extracted text and stored the result as a CSV that you can download from the GitHub repository.
Recently, Emil Hvitfeldt released ggpage, a package that lets you create a page-layout visualization using ggplot2. While the package uses the text content of the document only — so the visualized text layout doesn’t completely match the layout of the original document — it does allow you to highlight text elements, like mentions of any of the recurring cast of characters in Stupid Watergate.
The first step is to load the text version of the Mueller report. You can see from the first few lines of the data that the OCR really struggled with the header that appears at the top of each page and has been crossed out with a single line. (The redacted text is less confusing to the OCR because it’s rendered in solid black and generally results in blank space.)
# A tibble: 19,195 × 3
page line text
<dbl> <dbl> <chr>
1 1 1 "U.S. Department of Justice"
2 1 2 "AttarAe:,c\\\\'erlc Predtiet // Mtt; CeA1:ttiA"
3 1 3 "Ma1:ertalPrn1:eetedUAder Fed. R. Crhtt. P. 6(e)"
4 1 4 "Report On The Investigation Into"
5 1 5 "Russian InterferenceIn The"
6 1 6 "2016 PresidentialElection"
7 1 7 "Volume I of II"
8 1 8 "Special Counsel Robert S. Mueller, III"
9 1 9 "Submitted Pursuant to 28 C.F.R. § 600.8(c)"
10 1 10 "Washington, D.C."
# … with 19,185 more rows
The core of the next step is to pass the mueller_report to ggpage::ggpage_build(). Before doing that, though, I pad each page to make sure they have the same number of lines. The ggpage_build() function tokenizes the text into individual words, so I then use str_detect() to find mentions of the key players.
Finally, ggpage_plot() from ggpage creates the ggplot2 page layout, and adding the fill aesthetic using the manual color scale defined above adds color highlights for mentions of Trump, Russia, and others.